The current Covid-19 crisis brought public life to an abrupt halt. The German Bundesliga paused after its 25th match day. The last match was played on the 11th of March: A so called Geisterspiel between local rivals Gladbach and Köln in an empty Borussia-Park. Without cheering crowds, this derby, which Glabach won 2-1, had a somewhat eerie atmosphere. Amidst all discussion about how and when (or even if) the season should continue, I thought I could just build a simple statistical model and simulate the rest of the season. Admittedly, a simulation is even less exciting than a Geisterspiel. It is, however, a good way to show that any Bayesian model is a generative model, i.e. it is like a simulation.
In this post we will load data on goals scored so far in this Bundesliga season and transform it so that we can create tables of standings for all matches that were already played and use our statistical model for all matches that were not played yet. Next, we will specify and fit a Bayesian Poisson Generalized Linear Mixed Model (Poisson GLMM) which we will use to predict the rest of the season. These prediction are like a simulation of potential full Bundesliga season and see briefly investigate how this season could have played out.
Set-up and data wrangling
First, we will load the packages which we are going to use here. For the data wrangling part we will use the packages in the tidyverse. The modeling will be done using the rstanarm package.
library(tidyverse)
library(rstanarm)The data is readily available at football-data.co.uk. They provide a lot of betting odds data and some match statistics. We will ignore most if it, though. For now we will only use data on goals scored by each team. The D1-1920.csv is read in using the read_csv function from the readr package, which is part of the tidyverse. The correct date format is specified here so that it is recognized as a date (and not just some string). Then the relevant columns are selected.
buli1920 <- read_csv(
"D1-1920.csv",
col_types = cols(Date = col_date(format = "%d/%m/%Y"))) %>%
select(Date, HomeTeam:FTR)
DT::datatable(buli1920)The data contains 224 rows – all the matches that were played in the Bundesliga before Covid-19 brought everything to a halt. The column names for Date, HomeTeam, and AwayTeam are self-explanatory. The others are:
FTHG= Full Time Home Team GoalsFTAG= Full Time Away Team GoalsFTR= Full Time Result (H = Home Win, D = Draw, A = Away Win).
Normally, a full season with 18 teams has \(18 \times 17 = 306\) matches, so we are missing 82. Luckily, we do not have to write down all the matches we are missing. Using the crossing function, we create a data set of all combinations of HomeTeam and AwayTeam and then remove the cases where home and away teams are the same. (This reminds me of a smuggish remark by some Bayern Munich official who said that the Bayern training matches had more quality than most Bundesliga matches… but I digress.)
After creating the table of all possible matches, we join it with the data that we have. We arrange everything by date and add an arbitrary match identifier, match_id. Note that the missing matches do not have dates, but this is not a problem, since we are ignoring the time dimension for now. Along the way we converted the team columns to factor types with the same levels (that is why we created the sorted teams vector).
teams <- buli1920$HomeTeam %>%
unique() %>%
sort()
all_matches <- crossing(
HomeTeam = factor(teams),
AwayTeam = factor(teams)
) %>%
filter(HomeTeam != AwayTeam)
buli1920 <- buli1920 %>% mutate(
HomeTeam = factor(HomeTeam, levels = teams),
AwayTeam = factor(AwayTeam, levels = teams)) %>%
right_join(all_matches, by = c("HomeTeam", "AwayTeam")) %>%
arrange(Date) %>%
mutate(match_id = 1:n())
buli1920_obs <- buli1920 %>%
drop_na()
buli1920_mis <- buli1920 %>%
filter(is.na(Date))
nrow(buli1920_mis)[1] 82As expected, we see that the data frame containing the missing Bundesliga matches has 82 rows.
Right now the data is in what is called wide format. That means we have two columns for teams (home and away) and two columns for goals (again, home and away). All these columns literally make the data frame wide. However, for creating a Bundesliga table and for modeling match outcomes it will be useful to have the data in long format, i.e. less columns and more rows.
A relatively new addition to the tidyverse are the pivot_longer and pivot_wider functions. These help you to get from wide to long data frames and vice versa. Their options are a bit elaborate and I’m still getting used to them. I found the _spec versions of the functions extremely useful when things become a bit more complicated. With the _spec approach you first set up a data frame indicating how you want to pivot things. Let’s do this for our data set using the tribble function.
spec <- tribble(
~.value, ~.name , ~side,
"team" , "HomeTeam", "H" ,
"team" , "AwayTeam", "A" ,
"G" , "FTHG" , "H" ,
"G" , "FTAG" , "A" ,
"GA" , "FTAG" , "H" ,
"GA" , "FTHG" , "A"
)In the .value column we put the names of the new columns that we want to create. The .name column specifies the column names in the old data set which hold the values for the new created values. We then specify another variable (called side) that indicates whether the team (or goal G) is the home (H) or away (A) side. Notice that we create a goals against (GA) column in the process: We take the the away goals in the old data set (FTAG) and assign them to GA in the new data, while side == "H" indicates that these are the goals against the home side. Similarly for the home goals.
I’m not going to pretend that this is super obvious (at least it was not for me), but I think looking at the results makes everything a bit clearer.
buli1920_long_obs <- buli1920_obs %>%
pivot_longer_spec(spec)
DT::datatable(buli1920_long_obs, options = list(pageLength = 6))Each row now holds the name of a team and whether it played home or away (side), the goals it scored, G, and the goals scored against that team, GA. Now the match_id comes in handy as it helps us to keep track which rows belong together, i.e. to the same match.
We do the same for the data frame with the missing matches, but that’s not really interesting until we predict some new values.
buli1920_long_mis <- buli1920_mis %>%
pivot_longer_spec(spec)
head(buli1920_long_mis, 4)# A tibble: 4 x 7
Date FTR match_id side team G GA
<date> <chr> <int> <chr> <fct> <dbl> <dbl>
1 NA <NA> 225 H Augsburg NA NA
2 NA <NA> 225 A FC Koln NA NA
3 NA <NA> 226 H Augsburg NA NA
4 NA <NA> 226 A Hoffenheim NA NAWe remove the G column, which is full of NAs anyway, from the missing matches data frame for now, because this is what we later want to predict. (Otherwise the predict function, that we will use later, will complain that there is already a G column present.) We can keep FTR and GA and fill in the missing values after we predicted the goals column.
buli1920_long_mis <- buli1920_long_mis %>%
select(-G)But before we do that, let’s first re-create the Bundesliga table as it is right now. For that we write a little function, which we can reuse later. The function takes a data frame df as input and then calculates the points pts every team got each match and the goal difference GD for each team in each match. Then, everything is grouped by teams. The number of rows (n()) per team is the number of matches played by that team and all other columns are just summed up. We arrange the resulting data frame by points, goal difference and goals, all in descending order and add a positions, pos, column ranging from 1 to 18.
The function will be usable on the long version of the observed matches data frame.
gen_table <- function(df){
df %>%
mutate(
pts = case_when(FTR == "D" ~ 1,
FTR == side ~ 3,
FTR != side ~ 0),
GD = G - GA
) %>%
group_by(team) %>%
summarize(
played = n(),
pts = sum(pts),
G = sum(G),
GA = sum(GA),
GD = sum(GD),
.groups = "drop") %>%
arrange(
desc(pts),
desc(GD),
desc(G)
) %>%
bind_cols("pos" = 1:18, .)
}
pts_table_obs <- buli1920_long_obs %>%
gen_table()Let’s have a look at it.
| Team | Played | PTS | G | GA | GD | |
|---|---|---|---|---|---|---|
| 1 | Bayern Munich | 25 | 55 | 73 | 26 | 47 |
| 2 | Dortmund | 25 | 51 | 68 | 33 | 35 |
| 3 | RB Leipzig | 25 | 50 | 62 | 26 | 36 |
| 4 | M’gladbach | 25 | 49 | 49 | 30 | 19 |
| 5 | Leverkusen | 25 | 47 | 45 | 30 | 15 |
| 6 | Schalke 04 | 25 | 37 | 33 | 36 | -3 |
| 7 | Wolfsburg | 25 | 36 | 34 | 30 | 4 |
| 8 | Freiburg | 25 | 36 | 34 | 35 | -1 |
| 9 | Hoffenheim | 25 | 35 | 35 | 43 | -8 |
| 10 | FC Koln | 25 | 32 | 39 | 45 | -6 |
| 11 | Union Berlin | 25 | 30 | 32 | 41 | -9 |
| 12 | Ein Frankfurt | 24 | 28 | 38 | 41 | -3 |
| 13 | Hertha | 25 | 28 | 32 | 48 | -16 |
| 14 | Augsburg | 25 | 27 | 36 | 52 | -16 |
| 15 | Mainz | 25 | 26 | 34 | 53 | -19 |
| 16 | Fortuna Dusseldorf | 25 | 22 | 27 | 50 | -23 |
| 17 | Werder Bremen | 24 | 18 | 27 | 55 | -28 |
| 18 | Paderborn | 25 | 16 | 30 | 54 | -24 |
As a Werder Bremen fan the table is kind of depressing for me, though, so let’s quickly move on.
Modeling match outcomes
Before predicting goal scores and simulating the rest of the season, we have to come up with a model that generates those predictions. In this part of the series I will use a fairly simple model which will only consider team differences in the ability to score goals and the home advantage each team has and ignore, for example defensive capabilities of each team.
In the following section I will briefly go over the mathematical representation of the model. Feel free to skip this part. Then, I will fit the model using rstanarm. I will then summarize the main implications of the models in two plot showing the predicted expected number of goals (or xG) for each team, when they play home and away from home.
Formulating the model
Working with football data is nice, because the number of goals often match a Poisson distribution pretty closely. I therefore fit a Poisson Generalized Linear Mixed Model (GLMM) with a log-link function, one binary predictor home := (side == "H"), and two grouping variables (team with index \(t\) and match_id with index \(m\)). The likelihood for our data (scored goals \(G\)) can be written like this:
\[ \begin{align} G_i &\sim \text{Poisson}(\mu_i) \newline \log \mu_i &= \alpha_{t[i]} + \beta_{t[i]} \text{home}_i + \delta_{m[i]} \end{align} \]
The coefficient \(\alpha\) is the log expected number of goals when \(\text{home}=0\), i.e. it measures the expected number of goals when team \(t\) plays not at home. When team \(t\) does play at home, i.e. \(\text{home}=1\), then \(\beta\) is the additional effect of playing at home, i.e. the home advantage. It is really only an advantage if \(\beta>0\), which is a very reasonable assumption – however, I don’t restrict \(\beta\) to be positive.
The \(\delta\) is allowed to vary for each match. This will capture unobserved factors which affect both teams (in the same way) in a match. Unobserved here means stuff that is not explicitly in the model, i.e. weather conditions, time of day etc., but I don’t expect \(\delta\) to be big. Not because the aren’t possibly any systematic effects, which are not part of the model, but rather because \(\delta\) is an amalgamation of many smaller (and likely counteracting) effects.
Since \(\alpha\) and \(\beta\) are allowed to vary by team and \(\delta\) varies by match, we need to add some structure to the model, otherwise we would be horribly overfitting. Here comes the hierarchical part of the model into play.
\[ \begin{align} \delta_m &\sim \text{Normal}(0, \sigma_{M}^2) \newline \begin{bmatrix} \alpha \newline \beta \end{bmatrix}_t &\sim \text{MultiNormal} \left( \begin{bmatrix} \mu_\alpha \newline \mu_\beta \end{bmatrix}, \Sigma \right) \end{align} \]
All \(\delta_m\) come from the same distribution with common standard deviation \(\sigma_M\). Here, \(\sigma_M\) is like a hyper-parameter, or tuning parameter which controls the amount of heterogeneity across matches. If \(\sigma_M\) is high, we’d expect a high number of very low scoring games, e.g. 0-0, and a high number of high scoring games, e.g 4-5. When \(\sigma_M\) is low, the match outcomes will follow the estimated expected goals per team more closely.
Expected goals per team are estimated by \(\alpha\) and \(\beta\) which come from a Multivariate Normal distribution. The mean parameters \(\mu_\alpha\) and \(\mu_\beta\) represent the average of team expected goals away from home (\(\mu_\alpha\)) and the average of team home advantages (\(\mu_\beta\)). These effects are allowed to be correlated through the covariance matrix \(\Sigma\).
Now we have to set priors for these hierarchical parameters.
\[ \begin{align} \mu_\alpha &\sim \text{Normal}(0.4, 1^2) \newline \mu_\beta &\sim \text{Normal}(0.3, 0.5^2) \newline \sigma_M &\sim \text{Exponential}(1) \newline \Sigma &= \begin{bmatrix} \sigma_\alpha & 0 \newline 0 & \sigma_\beta \end{bmatrix} \Omega \begin{bmatrix} \sigma_\alpha & 0 \newline 0 & \sigma_\beta \end{bmatrix} \newline \sigma_\alpha, \sigma_\beta & \sim \text{Exponential}(1) \newline \Omega &\sim \text{LKJ}(1) \end{align} \]
I chose a prior for \(\mu_\alpha\) which implies that the median of the team expected goals away from home is roughly \(\exp(0.4) \approx 1.5\). This means, I expect half of the teams score less than 1.5 goals on average away from home and half of the teams score more than 1.5 goals, when playing away. The prior on \(\mu_\beta\) follows a similar logic. It is set so that \(\exp(0.4 + 0.3) \approx 2\) roughly half of the teams playing at home score less than 2 goals on average and the other half scores more than 2 on average when at home.
All other priors are rstanarm defaults – I think in reality rstanarm does something a little more complex, but this should essentially be what’s going on: The standard deviations \(\sigma_M, \sigma_\alpha, \sigma_\beta\) control the variability of the corresponding hierarchical parameters \(\delta, \alpha, \beta\). Their Exponential(1) priors are most likely too wide, but it’s better to err on the side of flexibility here.
The correlation matrix \(\Omega\) is given a LKJ(1) prior which is uniform in \((-1,1)\). The correlation between \(\alpha\) and \(\beta\) could be positive, since I’d reckon that good teams (high \(\alpha\)) play even better at home (high \(\beta\)). On the other hand, bad teams (low \(\alpha\)) could follow the strategy to just play good at home (high \(\beta\)) and don’t care so much about winning away matches which would imply a negative correlation. I guess the uniform prior is fine.
Running the model
We specified a probabilistic model, with a likelihood and priors. In Bayesian statistics we combine the likelihood of the data and our prior beliefs and compute the posterior distribution via Bayes rule.
\[p(\theta|D) = \frac{p(D|\theta) \times p(\theta)}{p(D)},\] or
\[\text{posterior} = \frac{\text{likelihood} \times \text{prior}}{\text{evidence}}\]
The posterior is thus a summary of what we know and belief about the world. If you are not familiar with Bayes theorem, you can check out this awesome video by Grant Sanderson.
Computing the posterior of non-trivial models is often extremely hard, if not impossible. But luckily we can use computers and well crafted programs to help us.
Now that we have formulated the model, let’s fit it.
Bayesian GLMMs can easily be run using the rstanarm::stan_glmer() function. The rstanarm package aims at offering Bayesian alternatives to frequently used frequentest methods – no pun intended. In this case it mimics the glmer function from the lme4 package, so we can use the lme4 formula syntax. rstanarm is build on Stan which is a probabilistic programming language for very efficient Markov Chain Monte Carlo (MCMC) – a way to produce samples from the posterior distribution of our model. Before we run the model we set the options to tell R that we have multiple cores available for MCMC.
options(mc.cores = parallel::detectCores())
poisson_glmm <- stan_glmer(
G ~ side + (side|team) + (1|match_id),
data = buli1920_long_obs,
family = poisson(link = "log"),
prior_intercept = normal(0.4, 1, autoscale = FALSE),
prior = normal(0.3, 0.5, autoscale = FALSE),
iter = 2000,
refresh = 500)The model ran without problems in about 20 seconds on my laptop and produced 4 Markov Chains with 1,000 draws from the posterior each. So for all parameters in our model we have 4,000 plausible values. Let’s see the results.
Results
poisson_glmmstan_glmer
family: poisson [log]
formula: G ~ side + (side | team) + (1 | match_id)
observations: 448
------
Median MAD_SD
(Intercept) 0.4 0.1
sideH 0.1 0.1
Error terms:
Groups Name Std.Dev. Corr
match_id (Intercept) 0.076
team (Intercept) 0.247
sideH 0.199 0.19
Num. levels: match_id 224, team 18
------
* For help interpreting the printed output see ?print.stanreg
* For info on the priors used see ?prior_summary.stanregThis summary should be looking familiar to anyone, who used the lme4 package before. It shows summary statistics of the posterior distribution for all parameters.
The posterior median for \(\alpha\) is 0.4. That’s really close to my prior belief! I’m a bit surprised – although, I probably shouldn’t be, but that’s a different and more philosophical debate. The posterior median for \(\beta\) is quite a bit lower than my prior belief. \(\beta\) is mostly positive though, so there is a measurable home advantage.
Match heterogeneity denoted by \(\delta\) in our model has a very low spread with the posterior median of \(\sigma_M\) being roughly 0.08. Variability across teams in \(\sigma_\alpha\) (median = 0.25) and \(\sigma_\beta\) (median = 0.20) is more prominent. However, I think it’s not surprising to find team differences.
Finally, we see that the correlation between scoring goals (away) and home advantage is positive (0.16): Better teams are expected to have an even bigger home advantage. This can also be seen when we plot the median expected goals for home and way matches of each team implied by the model.
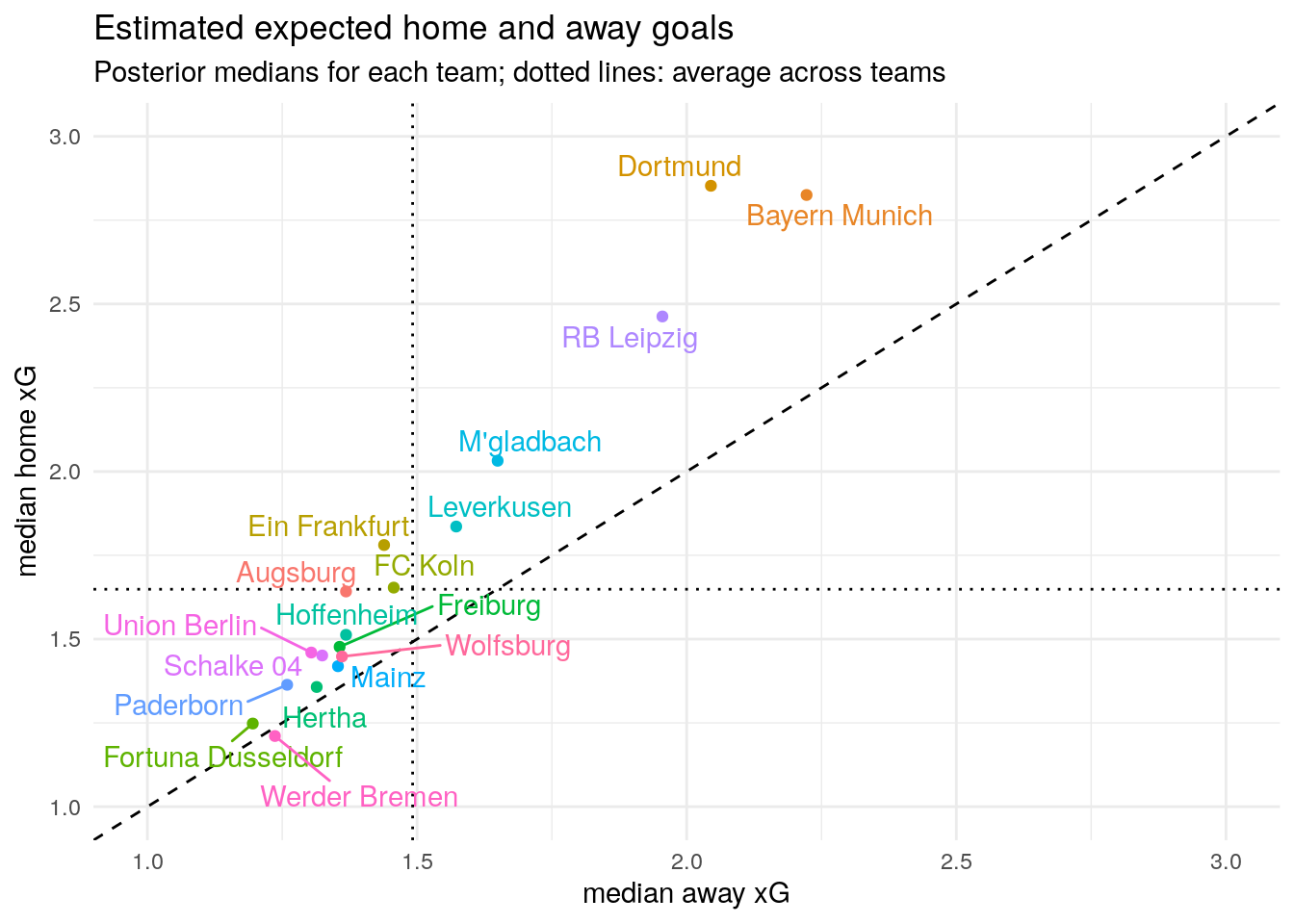
If a team lies on the dashed diagonal line, it’s expected goals will be the same in home and away matches. Teams that lie above the dashed line are expected to score more goals at home than away.
The home advantage is seen for nearly every team (except for Werder Bremen, who really struggled at home this season). We can also see that the cloud of points is tilted slightly above the 45 degree line. This is due to the positive correlation between \(\alpha_t\) and \(\beta_t\) in the model above: Dortmund, Bayern Munich, and RB Leipzig are expected to score more away goals than other teams and even more home goals relative to other teams. Low scoring teams such as Fortuna Düsseldorf, Werder Bremen, and Paderborn on the other hand do not have a strong home advantage – Werder Bremen even has a slight home disadvantage.
Since we estimated a full Bayesian model, we have complete quantification of uncertainty for all the parameters in the model. Instead of looking just at the medians, we can inspect the whole posterior expected goal distribution for each team.
This second plot draws contour lines for each team separately to avoid cluttering. If you are not familiar with contour lines, think of them as the height indications on a map, where the higher you go, the more probable is the location you are standing in. Location is just a specific combination of expected away goals and expected home goals and the “height” indicates how plausible this location is.
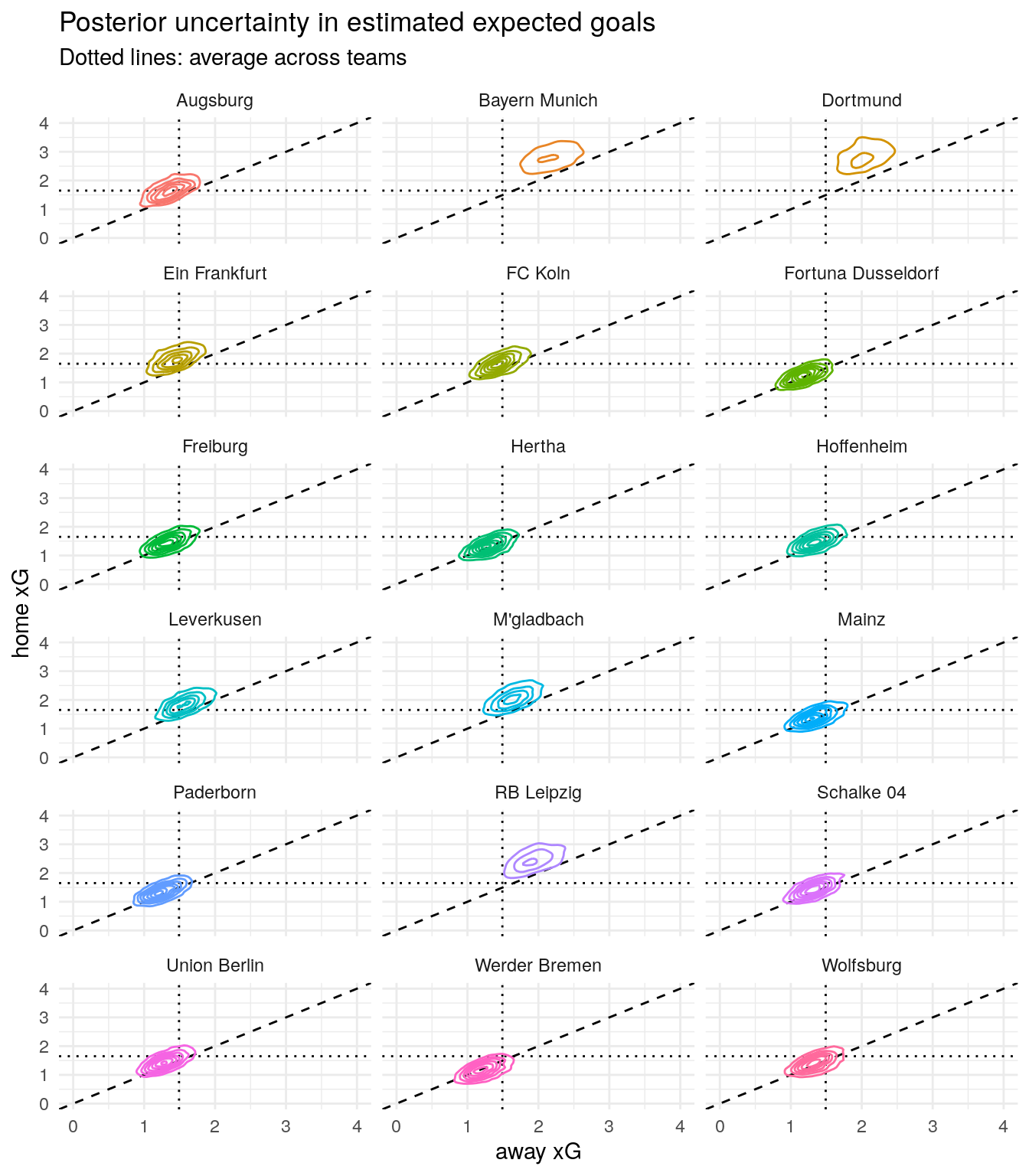
Here we can see differences between teams in a bit more detail.
For example, Bayern Munich and Borrusia Dortmund both score a lot of goals. Dortmund has the stronger home advantage, while Bayern is better at scoring away from home.
Comparing Gladbach and Leipzig we see that Leipzig tends to score more goals, but Gladbach has the clearer home advantage and scores a bit more consistently, which you can see in the slightly tighter contour lines.
Taking a look at the teams at the bottom of the table, Paderborn and Werder Bremen have comparable away goal expectations, while Bremen has a considerably lower range of plausible expected home goals, indicated by the contour lines which fall below the dashed diagonal line.
Simulating the Bundesliga
Now that we have a model for scoring goals, we can use it to predict outcomes of new matches. So we feed the model and the data for the matches that are still missing in the Bundesliga buli1920_long_mis into the posterior_predict function. We will just generate 3 draws from the posterior predictive distribution for the missing data.
n_sims <- 3
pp <- posterior_predict(
poisson_glmm,
newdata = buli1920_long_mis,
draws = n_sims
)The result is an array of dimension 3 (number of draws) by 164 (number of rows in buli1920_long_mis – remember that the data is in long format).
This is not very handy, so let’s write a little helper function. It will take one row from this new array, transform into the long format we used above, add the data for all observed matches and return a big data frame for all matches (observed and simulated) in long format. This function also takes care of the fact that the predicted goals, G, for each team in each match is the predicted goals against, GA, for the other team in that match.
gen_dataset <- function(i){
bind_cols(buli1920_long_mis, G = pp[i,]) %>%
group_by(match_id) %>%
mutate(
FTR = if_else(diff(G) == 0, "D", side[which.max(G)]),
GA = sum(G) - G
) %>%
bind_rows(buli1920_long_obs, .) %>%
mutate(sim = i) %>%
return()
}We can apply the function to our three posterior predictive draws and generate three whole seasons with observed and simulated data in long format.
Simulation 1
Simulation 2
Simulation 3
For the matches that were actually played the data is the same across simulations. It only differs in the simulated matches. One example is the simulated match Wolfsburg - Freiburg with three potential outcomes predicted from our model.
map_df(1:n_sims, ~ gen_dataset(.) %>% tail(2))# A tibble: 6 x 8
Date FTR match_id side team G GA sim
<date> <chr> <int> <chr> <fct> <dbl> <dbl> <int>
1 NA H 306 H Wolfsburg 2 1 1
2 NA H 306 A Freiburg 1 2 1
3 NA H 306 H Wolfsburg 4 2 2
4 NA H 306 A Freiburg 2 4 2
5 NA H 306 H Wolfsburg 1 0 3
6 NA H 306 A Freiburg 0 1 3We previously created the gen_table() function which takes in a data frame of match results in long format and returns a table of Bundesliga standings. Using this function on the result of gen_dataset() will give us an end of season table for the observed matches and one draw of the posterior predictive, i.e. one simulation, for all the missing matches.
When we do this repeatedly, we get many possible outcomes for the rest of this Bundesliga season holding constant all observed matches. Before we do this, let’s dial up the number of simulations. The most reasonable number for n_sim would be to just use all of our posterior draws from the model fit.
n_sims <- poisson_glmm$stanfit@stan_args %>%
map(~ pluck(., "iter") - pluck(., "warmup")) %>%
unlist() %>%
sum()
pp <- posterior_predict(
poisson_glmm,
newdata = buli1920_long_mis,
draws = n_sims
)
sim_tables <- map_df(
1:n_sims,
~ gen_dataset(.) %>%
# using the gen_table function created above
gen_table,
.id = "sim")
sim_tables# A tibble: 72,000 x 8
sim pos team played pts G GA GD
<chr> <int> <fct> <int> <dbl> <dbl> <dbl> <dbl>
1 1 1 Dortmund 34 76 96 46 50
2 1 2 Bayern Munich 34 72 98 43 55
3 1 3 RB Leipzig 34 64 82 41 41
4 1 4 Leverkusen 34 63 61 43 18
5 1 5 M'gladbach 34 58 60 44 16
6 1 6 FC Koln 34 55 56 53 3
7 1 7 Freiburg 34 48 51 56 -5
8 1 8 Schalke 04 34 47 45 49 -4
9 1 9 Union Berlin 34 45 47 51 -4
10 1 10 Hoffenheim 34 45 43 56 -13
# … with 71,990 more rowsThis resulted in a data frame with \(18 \times 4000 = 72000\) rows, where each simulated end of season table is indexed by sim. We can now plot all resulting ranks for each team.
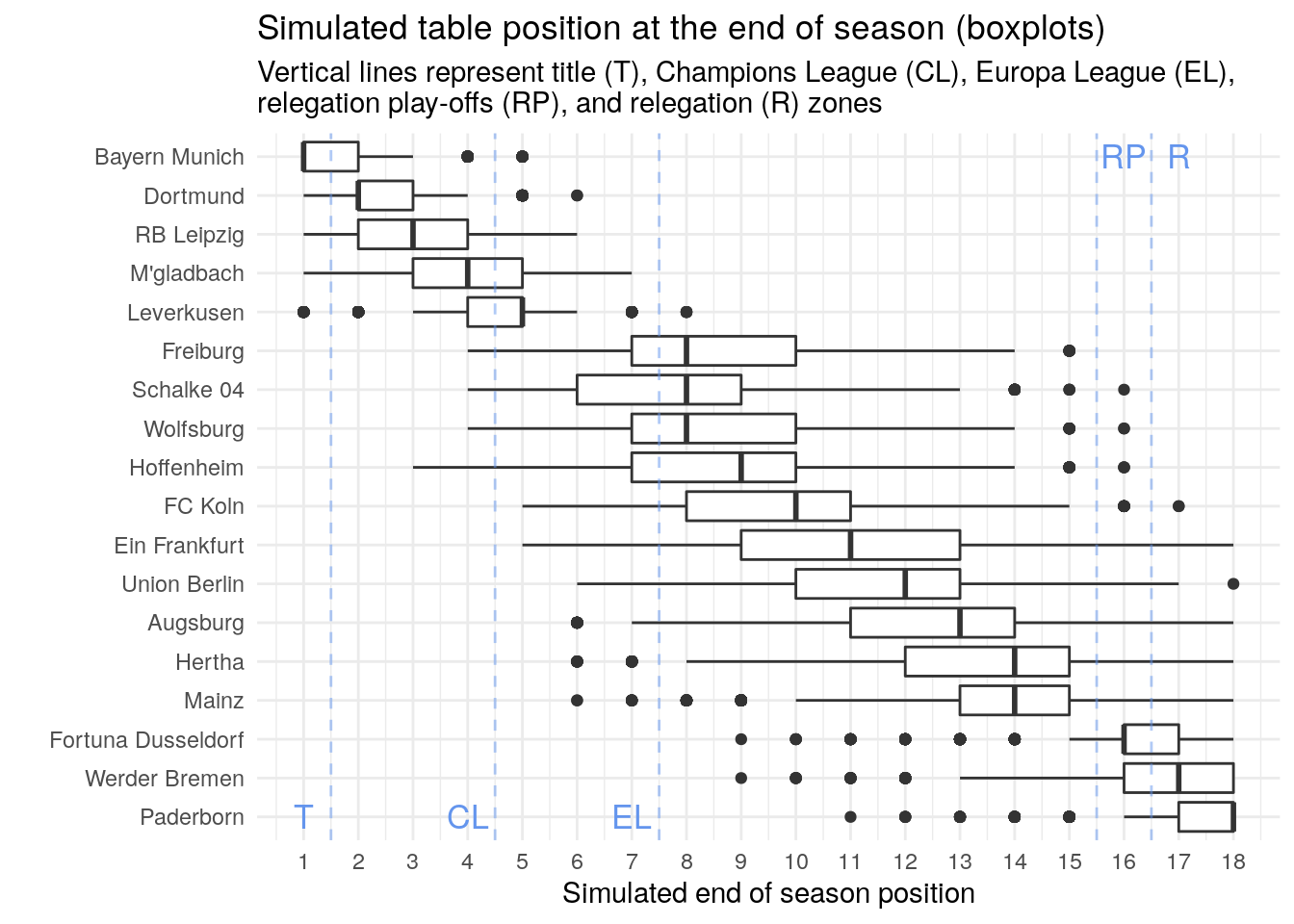
The boxplots show where most of the simulated ranks fall. The lines is the median posterior rank of each team, the boxes contain 50% of all simulated values. The whiskers span ±1.5 IQR (inter quartile range). Dots represent outliers, or very unlikely results of the simulations.
It looks like there are three groups of teams: The first group are most likely finishing the season in positions 1 to 5 (Bayern Munich to Bayer Leverkusen). Another group are the three teams at the bottom of the table (Düsseldorf, Bremen, Paderborn). All other teams will probably end up in the middle of the table, where some fight for Europa League spots (Schalke, Freiburg, Wolfsburg, and Hoffenheim).
We can also plot the probability for each team to end in a specific spot in the table.
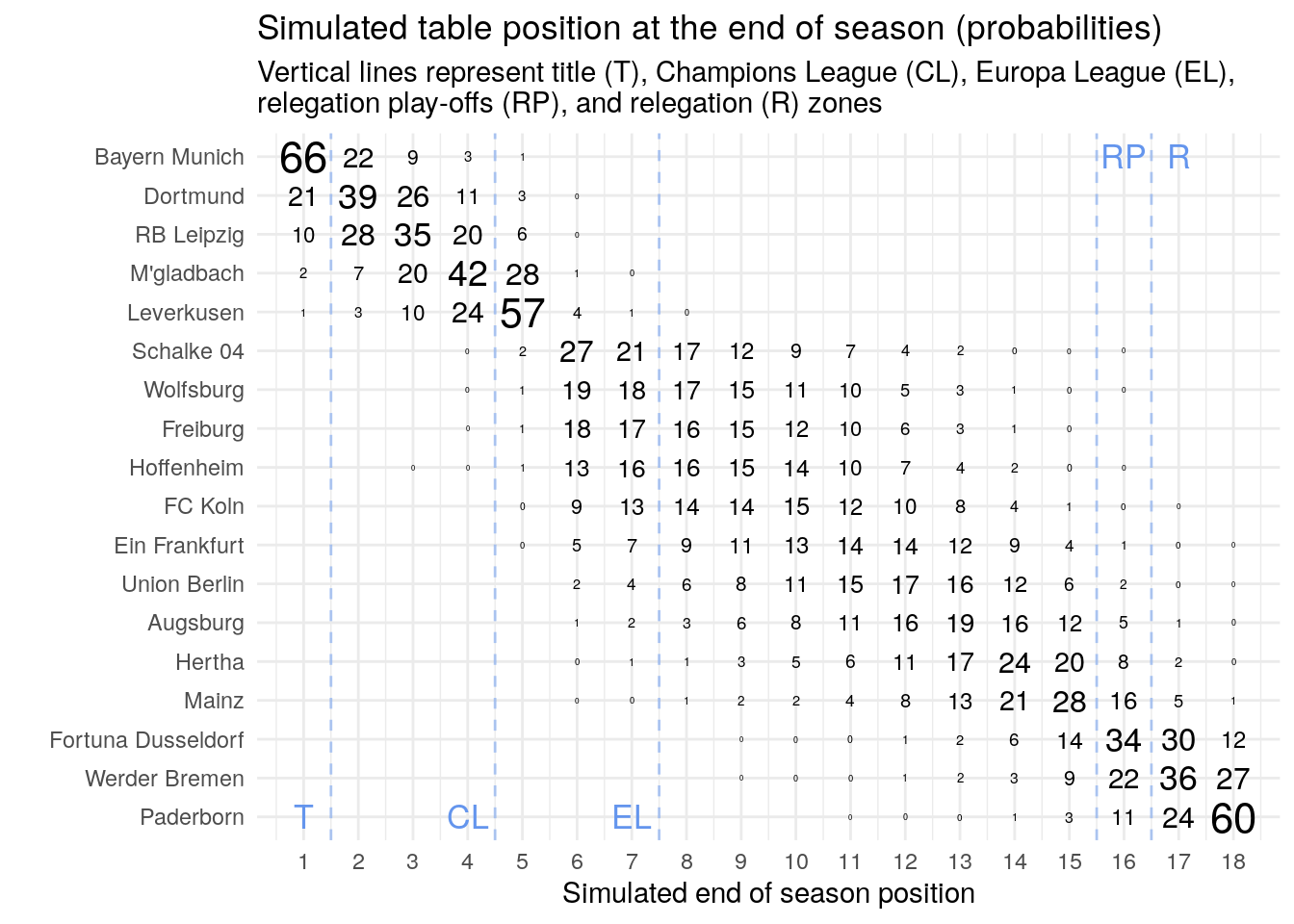
These probabilities are only really high at both ends of the table, since the possible ranks that the teams can reach there are limited – you can not be better than first place or worse than last, obviously.
Bayern has a two in three chance of winning the league, while Paderborn has a three in five chance of being directly relegated to the second tier. Interestingly, Düsseldorf has a roughly one in three chance of going into relegation play-offs and Leverkusen has a three in five chance of finishing in the best non-CL spots (5th position).
Since these are valid probabilities, we can add them up for each interesting part of the table (winning the title, CL, EL, relegation play-offs, and immediate relegation).
| Win League | Champions League | Europa League | Mid Table | Relegation Play-offs | Relegation | |
|---|---|---|---|---|---|---|
| Bayern Munich | 66 | 99 | 1 | |||
| Dortmund | 21 | 97 | 3 | |||
| RB Leipzig | 10 | 93 | 7 | |||
| M’gladbach | 2 | 71 | 28 | |||
| Leverkusen | 1 | 39 | 62 | 0 | ||
| Schalke 04 | 50 | 50 | 0 | |||
| Wolfsburg | 38 | 62 | 0 | |||
| Freiburg | 37 | 63 | ||||
| Hoffenheim | 30 | 70 | 0 | |||
| FC Koln | 22 | 77 | 0 | 0 | ||
| Ein Frankfurt | 12 | 86 | 1 | 0 | ||
| Union Berlin | 6 | 91 | 2 | 0 | ||
| Augsburg | 3 | 91 | 5 | 1 | ||
| Hertha | 1 | 88 | 8 | 3 | ||
| Mainz | 0 | 78 | 16 | 6 | ||
| Fortuna Dusseldorf | 24 | 34 | 42 | |||
| Werder Bremen | 15 | 22 | 63 | |||
| Paderborn | 4 | 11 | 84 |
We now see that Paderborns risk of immediate relegation is quite high. Also Werder Bremen has a roughly two in three chance of being relegated to second division directly.
Collapsing the table also shows that many teams will finish in the middle of the table with very high probability. Union Berlin for example has a more than 9 out of 10 chance to end up mid table, which can be considered a big success for them.
The CL spots are very likely going to the top four teams. Only Bayer Leverkusen might have a chance to snack a spot and send Gladbach into EL.
The Europa League will be the most contested place in the table. More than a handful of teams have a realistic chance to grab one of these spots, but they will most likely go to Leverkusen, Schalke, and Wolfsburg, leaving Freiburg and Hoffenheim close behind.
When the Bundesliga shut down due to the Covid-19 crisis, it was not really clear if the 2019 / 2020 season would be finished at all. I was asking myself, who would be in favor of stopping the season and who would be in favor of playing on? (Setting aside all valid health concerns, the monetary incentive to play a match, and any special rules like no-relegation in case of stopping the season, of course.) The question mainly boils down to: If the season were to continue, would my team be expected to finish higher up the table, or lower?
| Team | same | lower | higher | |
|---|---|---|---|---|
| 1 | Bayern Munich | 66.1 | 33.9 | 0.0 |
| 2 | Dortmund | 39.5 | 39.8 | 20.8 |
| 3 | RB Leipzig | 35.1 | 26.7 | 38.2 |
| 4 | M’gladbach | 41.5 | 28.4 | 30.1 |
| 5 | Leverkusen | 57.0 | 4.8 | 38.2 |
| 6 | Schalke 04 | 26.9 | 70.9 | 2.2 |
| 7 | Wolfsburg | 17.8 | 61.9 | 20.3 |
| 8 | Freiburg | 16.2 | 46.9 | 36.8 |
| 9 | Hoffenheim | 15.4 | 38.1 | 46.5 |
| 10 | FC Koln | 14.9 | 35.2 | 49.9 |
| 11 | Union Berlin | 14.8 | 53.8 | 31.4 |
| 12 | Ein Frankfurt | 14.2 | 26.4 | 59.4 |
| 13 | Hertha | 17.4 | 55.9 | 26.6 |
| 14 | Augsburg | 16.5 | 18.4 | 65.1 |
| 15 | Mainz | 28.0 | 21.9 | 50.1 |
| 16 | Fortuna Dusseldorf | 33.9 | 41.9 | 24.2 |
| 17 | Werder Bremen | 36.2 | 26.9 | 37.0 |
| 18 | Paderborn | 60.0 | 0.0 | 40.0 |
The ordering in this table is the same as above for the observed matches, the same column states the model based probability of finishing the season in the same spot as when it was paused. If the probability of finishing higher is greater than the probability of finishing lower, you should prefer playing the season until the end. If it’s the other way around, you should prefer stopping the season right now.
There are some obvious choices here, for example Bayern Munich would be fine to end the season and win the title, while Paderborn has nothing to lose playing through the season and maybe preventing relegation. It might be not so obvious for Gladbach: Of course the probability is higher to finish in a better position, but there is a non-negligible risk of dropping to the fifth place and play EL instead of playing CL next season.
Wrapping up
In this post, we created a table of Bundesliga standings for all matches that have been played in this season so far. We transformed the data to be in long format to use it modeling the expected number of goals per team. We formulated and fitted a hierarchical Bayesian model for goal scoring. However, we did not consider defensive strengths of teams or any other additional information apart from home advantage. Finally, we used the models predictions to simulate how the Bundesliga could have played out and summarized the results in various ways.
In the next part of this series, I will make the model a bit more interesting and incorporate defensive capabilities of teams. For this, we will write our very own Stan model code. So stay tuned!